pmr
C++ 17 引入了内存相关的一系列可重写的 API。 在头文件 memory_resource 中。命名空间在 std::pmr:: ,目的在于
- 池化内存分配,减少频繁系统调用分配或释放内存,带来的性能损失
- 与已有 std 中的 allocator, container 结合,方便使用者自定义相关的内存分配策略类
- 特殊的使用场景:内存分配效率敏感、需要禁用内存分配。如因功能安全需要,自动驾驶代码禁止动态内存分配
标准库的主要结构如下
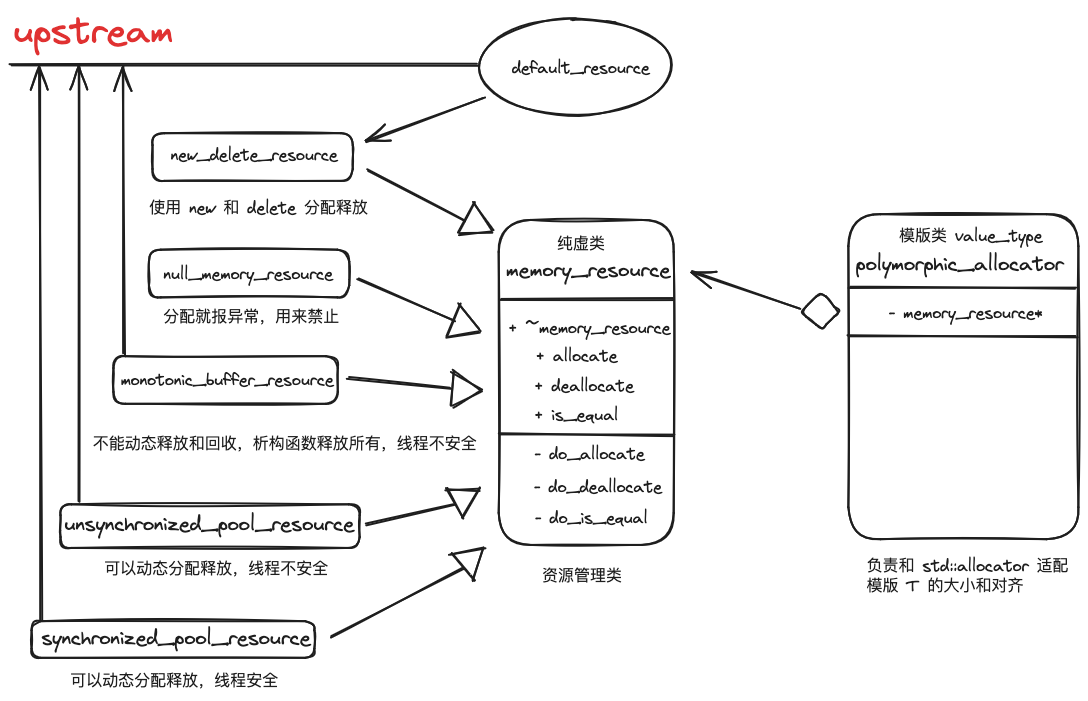
memory_resource 为分配释放内存的管理类,allocator 和类型相关,向 memory_resource 索取内存,因此构造 allocator 时候需要传入 upstream 即 memory_resource 的指针
标准库实现的内存分配类
- std::pmr::monotonic_buffer_resource
- std::pmr::unsynchronized_pool_resource
- std::pmr::synchronized_pool_resource
获取默认的 new delete 内存分配策略,继承自 memory_resource。作为基准测试(clang++ 下为 __new_delete_memory_resource_imp)
std::pmr::new_delete_resource()
分配内存调用 allocate 会直接抛出异常 std::bad_alloc(),通常用来禁止向 upstream 索要内存,从而禁止从默认的内存分配类索取内存
std::pmr::null_memory_resource()
获取默认的内存分配策略类,不修改则为 new_delete_resource
std::pmr::get_default_resource()
设置默认的内存分配策略类
std::pmr::set_default_resource(memory_resource*)
std 库封装的接口
封装了 polymorphic_allocator 满足了 std 容器中需要满足的条件,如定义了 value_type,operaotr== 比较两个分配器是否相等。
封装了一些数据结构,如std::pmr::vector<T> 实际上是 std::list<T, std::pmr::polymorphic_allocator<T>>
这时候可以直接给他传入你的 buf, std::pmr::list{&upstream}; upstream 即 memory_resource 实现类,upstream 会传递给 allocator
测试
计时函数
1 | template <typename F, typename... Args> |
优化 list
1 | std::array<std::byte, 65536 * 24> buf; |
0.00803458s
0.00369133s
0.00206471s
注意点
如果用 set_default_resource 修改了默认的分配池,该 memory_resource 的生命期需要注意
实现解析,以 clang++ 为例
monotonic_buffer_resource 是一个链表,每个节点是单调递减的

- 如果用户指定 buf,则对 buf 的管理类似上图,但是没有 footer,直到 cur 减少到达 start
- 没有指定 buf,则从 upstream 分配上图的 chunk + footer 块
- 2 倍指数级申请新的 chunk
do_deallocate 不做任何动作,在析构函数里一次性 release 所有 chunk。适用于需要不停分配,但一次性释放的场景,线程不安全
unsynchronized_pool_resource
1 | __adhoc_pool __adhoc_pool_; |
其中主要实现了 adhoc pool,adhoc pool 主要是和 upstream 交流。申请超大内存时,会由 upstream 分配释放,小内存则会提供内部满足容量中最小的 fixed pool
fixed pools 在首次分配时,会构造内存相邻的多个 fixed pool 指针,可以对请求的内存容量求 log2() 得到下标(2^n 就是该 fixed pool 的容量),进行偏移访问,从而可用的 fixed pool 链表
释放内存时,超大内存由 upstream 申请的,交由 upstream 释放。fixed pool 管理的只会添加到给该容量的 fixed pool 链表中,等待下一次使用。fixed pool 实现类似上面 chunk 和 footer,但是没有 cur。
可以指定 pool options,largest_required_pool_block 求对数后得到 fixed pool 个数, max_blocks_per_chunk 指的 fixed pool 的最大容量
synchronized_pool_resource 在开启多线程情况下,对 unsynchronized_pool_resource 封装了一层锁